2.1 One hot encoding
2.2 Count and Frequency encoding
2.3 Target encoding / Mean encoding
2.4 Ordinal encoding
2.5 Weight of Evidence
2.6 Rare label encoding
2.7 Helmert encoding
2.8 Probability Ratio Encoding
2.9 Label encoding
2.10 Feature hashing
2.11 Binary encoding & BaseN encoding
將使用這個data-frame,有兩個獨立變數或特徵(features)和一個標籤(label or Target),共有十筆資料。
import pandas as pd
import numpy as np
data = {'Temperature': ['Hot','Cold','Very Hot','Warm','Hot','Warm','Warm','Hot','Hot','Cold'],
'Color': ['Red','Yellow','Blue','Blue','Red','Yellow','Red','Yellow','Yellow','Yellow'],
'Target':[1,1,1,0,1,0,1,0,1,1]}
df = pd.DataFrame(data, columns = ['Temperature', 'Color', 'Target'])
Rec-No | Temperature | Color | Target |
------------- | -------------------------- | -------------
0 | Hot | Red | 1
1 | Cold | Yellow | 1
2 | Very Hot | Blue | 1
3 | Warm | Blue | 0
4 | Hot | Red | 1
5 | Warm | Yellow | 0
6 | Warm | Red | 1
7 | Hot | Yellow | 0
8 | Hot | Yellow | 1
9 | Cold | Yellow | 1
Feature hashing 使用雜湊季技巧(hashing trick),將一個類別性質的欄位轉換成多個欄位,在轉換時,我們可以定義要轉換成幾個新欄位,而新欄位的數目可小於類別的數目,也就是小於使用One Hot Encoding產生的欄位數目。
使用 scikit-learn 來轉換:
from sklearn.feature_extraction import FeatureHasher
fh = FeatureHasher(n_features=3, input_type='string')
hashed = fh.transform(df[['Temperature']].astype(str).values)
hashed = pd.DataFrame(hashed.todense())
hashed.columns = ['Temp_fh'+str(i) for i in hashed.columns]
pd.concat([df, hashed], axis=1)
| / | Temperature | Color | Target | Temp_fhcol_0 | Temp_fhcol_1 | Temp_fhcol_2 |
|---|---|---|---|---|---|---|
| 0 | Hot | Red | 1 | -1.0 | 0.0 | 0.0 |
| 1 | Cold | Yellow | 1 | 0.0 | 0.0 | 1.0 |
| 2 | Very Hot | Blue | 1 | 0.0 | 0.0 | -1.0 |
| 3 | Warm | Blue | 0 | 0.0 | -1.0 | 0.0 |
| 4 | Hot | Red | 1 | -1.0 | 0.0 | 0.0 |
| 5 | Warm | Yellow | 0 | 0.0 | -1.0 | 0.0 |
| 6 | Warm | Red | 1 | 0.0 | -1.0 | 0.0 |
| 7 | Hot | Yellow | 0 | -1.0 | 0.0 | 0.0 |
| 8 | Hot | Yellow | 1 | -1.0 | 0.0 | 0.0 |
| 9 | Cold | Yellow | 1 | 0.0 | 0.0 | 1.0 |
使用 category_encoders 來轉換:
import category_encoders as ce
Hashing_encoder = ce.HashingEncoder(n_components=3, cols=['Temperature'])
hashed = Hashing_encoder.fit_transform(df['Temperature'])
hashed.columns = ['Temp_fh'+str(i) for i in hashed.columns]
df = pd.concat([df, hashed], axis=1)
df
| / | Temperature | Color | Target | Temp_fhcol_0 | Temp_fhcol_1 | Temp_fhcol_2 |
|---|---|---|---|---|---|---|
| 0 | Hot | Red | 1 | 0 | 0 | 1 |
| 1 | Cold | Yellow | 1 | 0 | 1 | 0 |
| 2 | Very Hot | Blue | 1 | 0 | 1 | 0 |
| 3 | Warm | Blue | 0 | 1 | 0 | 0 |
| 4 | Hot | Red | 1 | 0 | 0 | 1 |
| 5 | Warm | Yellow | 0 | 1 | 0 | 0 |
| 6 | Warm | Red | 1 | 1 | 0 | 0 |
| 7 | Hot | Yellow | 0 | 0 | 0 | 1 |
| 8 | Hot | Yellow | 1 | 0 | 0 | 1 |
| 9 | Cold | Yellow | 1 | 0 | 1 | 0 |
Binary encoding 是將一個類別轉換成二進位數字(binary digits),每一個二進位數字將會建立一個特徵欄位(feature column),假如我們有 n 個類別,那麼binary encoding將只產生 log(base 2)ⁿ 個欄位。
在我們例子中,我們有4個類別,因此只會產生3個新欄位。
轉換步驟:先將類別轉換成整數,接著,將這整數轉成二進位數字,最後將每一二進位數字分開成單獨欄位。
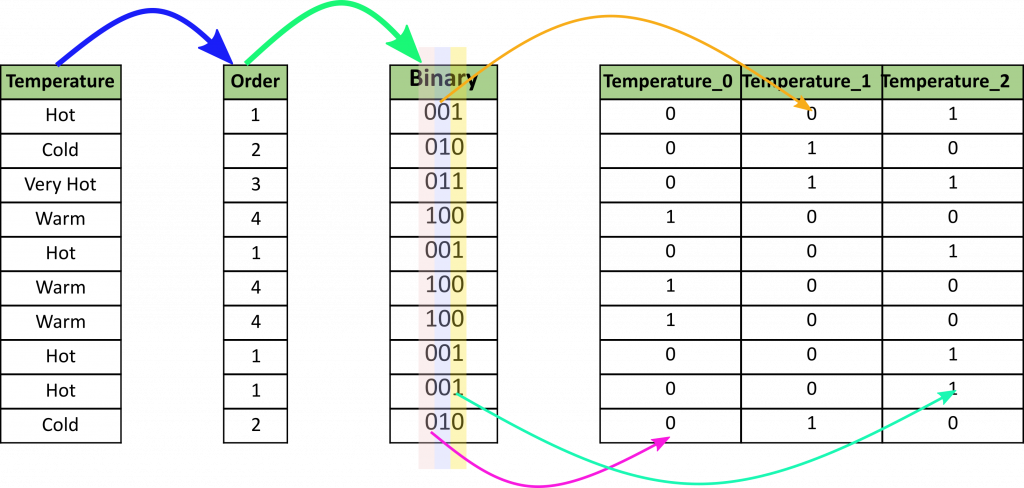
圖片來源:https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
在上圖中會發現,有的新欄位 1 的值出現在不同的類別中,這不是一個好現象,因為機器學習模型會認為這些類別有相同的性質,但實際上,有 1 出現是轉換技術的原因。
使用 category_encoders 來轉換:
mport category_encoders as ce
Binary_encoder = ce.BinaryEncoder()
df_be = Binary_encoder.fit_transform(df['Temperature'])
df_be.columns = ['be_'+str(i) for i in df_be.columns]
df = pd.concat([df, df_be], axis=1)
df
| / | Temperature | Color | Target | be_Temperature_0 | be_Temperature_1 | be_Temperature_2 |
|---|---|---|---|---|---|---|
| 0 | Hot | Red | 1 | 0 | 0 | 1 |
| 1 | Cold | Yellow | 1 | 0 | 1 | 0 |
| 2 | Very Hot | Blue | 1 | 0 | 1 | 1 |
| 3 | Warm | Blue | 0 | 1 | 0 | 0 |
| 4 | Hot | Red | 1 | 0 | 0 | 1 |
| 5 | Warm | Yellow | 0 | 1 | 0 | 0 |
| 6 | Warm | Red | 1 | 1 | 0 | 0 |
| 7 | Hot | Yellow | 0 | 0 | 0 | 1 |
| 8 | Hot | Yellow | 1 | 0 | 0 | 1 |
| 9 | Cold | Yellow | 1 | 0 | 1 | 0 |
BaseN encoding 基本上和 Binary encoding 相同, 不同點在於它使用 2 以外的整數當基數(base)。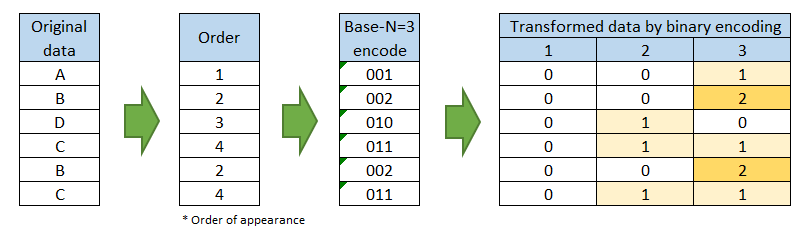
圖片來源:https://towardsdatascience.com/catalog-of-variable-transformations-to-make-your-model-works-better-7b506bf80b97
使用BaseN encoding時,當基數增加,新的欄位就會減少;這也意味比起Binary encoding有更多的重複資訊在新欄位, 這對機器學習模型有潛在的不良影響。當 BaseN=1 時,BaseN encoding 就等於 one hot encoding。假如 N 是無限大時,BaseN encoding 就和 label encoding 有相同結果。
BaseN encoding 存在的理由,可能是要讓 grid searching 較容易進行,所以 BaseN encoding 可以和 scikit-learn 的 gridsearchCV 搭配使用。
category_encoders 支援 BaseN encoding:
import category_encoders as ce
BaseN_encoder = ce.BaseNEncoder(base=3)
df_bne = BaseN_encoder.fit_transform(df['Temperature'])
df_bne.columns = ['bne_'+str(i) for i in df_bne.columns]
df = pd.concat([df, df_bne], axis=1)
df
| / | Temperature | Color | Target | bne_Temperature_0 | bne_Temperature_1 | bne_Temperature_2 |
|---|---|---|---|---|---|---|
| 0 | Hot | Red | 1 | 0 | 0 | 1 |
| 1 | Cold | Yellow | 1 | 0 | 0 | 2 |
| 2 | Very Hot | Blue | 1 | 0 | 1 | 0 |
| 3 | Warm | Blue | 0 | 0 | 1 | 1 |
| 4 | Hot | Red | 1 | 0 | 0 | 1 |
| 5 | Warm | Yellow | 0 | 0 | 1 | 1 |
| 6 | Warm | Red | 1 | 0 | 1 | 1 |
| 7 | Hot | Yellow | 0 | 0 | 0 | 1 |
| 8 | Hot | Yellow | 1 | 0 | 0 | 1 |
| 9 | Cold | Yellow | 1 | 0 | 0 | 0 |

